Take-home Exercise 2: Applied Spatial Interaction Models - A case study of Singapore public bus commuter flows
1 Overview
Urban mobility, characterized by the daily commute of urban dwellers from homes to workplaces, presents complex challenges for transport operators and urban managers. Traditional approaches to understanding these mobility patterns, such as commuter surveys, are often hindered by high costs, time-consuming processes, and the rapid obsolescence of collected data. However, the digitalization of city-wide urban infrastructures, including public buses, mass rapid transits, and other utilities, alongside the advent of pervasive computing technologies like GPS and SMART cards, offers a new paradigm in tracking and analyzing urban movement.
Objectives
This assignment is driven by two primary motivations. First, despite the growing availability of open data for public use, there is a noticeable gap in applied research demonstrating how these diverse data sources can be effectively integrated and analyzed to inform policy-making decisions. Second, there is a need to showcase how GDSA can be utilized in practical decision-making scenarios.
The core task of this assignment is to conduct a case study that exhibits the potential value of GDSA. By leveraging publicly available data from multiple sources, the goal is to build spatial interaction models that unravel the factors influencing urban mobility patterns, particularly focusing on public bus transit. This exercise aims to bridge the gap between the abundance of geospatially-referenced data and its practical application, thereby enhancing the return on investment in data collection and management, and ultimately supporting informed policy-making in urban mobility.
The specific tasks of this take-home exercise are as follows:
Geospatial Data Science
Derive an analytical hexagon data of 375m (this distance is the perpendicular distance between the centre of the hexagon and its edges) to represent the traffic analysis zone (TAZ).
With reference to the time intervals provided in the table below, construct an O-D matrix of commuter flows for a time interval of your choice by integrating Passenger Volume by Origin Destination Bus Stops and Bus Stop Location from LTA DataMall. The O-D matrix must be aggregated at the analytics hexagon level
Peak hour period Bus tap on time Weekday morning peak 6am to 9am Weekday afternoon peak 5pm to 8pm Weekend/holiday morning peak 11am to 2pm Weekend/holiday evening peak 4pm to 7pm Display the O-D flows of the passenger trips by using appropriate geovisualisation methods (not more than 5 maps).
Describe the spatial patterns revealed by the geovisualisation (not more than 100 words per visual).
Assemble at least three propulsive and three attractiveness variables by using aspatial and geospatial from publicly available sources.
Compute a distance matrix by using the analytical hexagon data derived earlier.
Spatial Interaction Modelling
Calibrate spatial interactive models to determine factors affecting urban commuting flows at the selected time interval.
Present the modelling results by using appropriate geovisualisation and graphical visualisation methods. (Not more than 5 visuals)
With reference to the Spatial Interaction Model output tables, maps and data visualisation prepared, describe the modelling results. (not more than 100 words per visual).
2 Loading Packages
The following packages will be used for this exercise:
| Package | Description |
|---|---|
| tmap | For thematic mapping |
| sf & sp | For importing, integrating, processing, and transforming geospatial data |
| tidyverse | For non-spatial data wrangling |
| DT | For creating and working with html tables |
| performance | For computing model comparison metrics |
| reshape2 | For data transformation between wide and long formats |
| ggpubr and gtsummary | For creating publication quality analytical and summary tables |
| stplanr | For transport planning and analysis |
| knitr | For dynamic report generation |
| scales | For scaling graphs |
| corrplot | For visualising correlation matrix |
| plotly | For interactive and dynamic plots |
The code chunk below, using p_load function of the pacman package, ensures that packages required are installed and loaded in R.
3 Data Preparation
For the purpose of this assignment, the following data will be used:
| Type | Name | As of Date | Format | Source | |
| 1 | Aspatial | Passenger Volume by Origin Destination Bus Stops | Oct 2023 | .csv | LTA DataMall |
| 2 | Aspatial | School Directory and Information (General information of schools) | Mar 2022 | .csv | Data.gov.sg |
| 3 | Aspatial | HDB Property Information (Geocoded) | Sep 2021 | .csv | Courtesy of Prof T. S. Kam |
| 4 | Geospatial | Bus Stop Location | Jul 2023 | .shp | LTA DataMall |
| 5 | Geospatial | Train Station Exit Point | Aug 2023 | .shp | LTA DataMall |
| 6 | Geospatial | Master Plan 2019 Subzone Boundary | 2019 | .shp | Courtesy of Prof T.S. Kam |
| 7 | Geospatial | Business (incl. industrial parks), FinServ, Leisure&Recreation and Retails (Geospatial data sets of the locations of business establishments, entertainments, food and beverage outlets, financial centres, leisure and recreation centres, retail and services stores/outlets compiled for urban mobility study) | .shp | Courtesy of Prof T.S. Kam |
3.1 O-D Data
Passenger Volume by Origin Destination Bus Stops dataset for October 2023, downloaded from LTA DataMall by using read_csv() or readr package.
glimpse() of the dplyr package allows us to see all columns and their data type in the data frame.
Rows: 5,694,297
Columns: 7
$ YEAR_MONTH <chr> "2023-10", "2023-10", "2023-10", "2023-10", "2023-…
$ DAY_TYPE <chr> "WEEKENDS/HOLIDAY", "WEEKDAY", "WEEKENDS/HOLIDAY",…
$ TIME_PER_HOUR <dbl> 16, 16, 14, 14, 17, 17, 17, 7, 14, 14, 10, 20, 20,…
$ PT_TYPE <chr> "BUS", "BUS", "BUS", "BUS", "BUS", "BUS", "BUS", "…
$ ORIGIN_PT_CODE <chr> "04168", "04168", "80119", "80119", "44069", "2028…
$ DESTINATION_PT_CODE <chr> "10051", "10051", "90079", "90079", "17229", "2014…
$ TOTAL_TRIPS <dbl> 3, 5, 3, 5, 4, 1, 24, 2, 1, 7, 3, 2, 5, 1, 1, 1, 1…Observations:
- There are 7 variables in the odbus tibble data, they are:
- YEAR_MONTH: Month in which data is collected
- DAY_TYPE: Weekdays or weekends/holidays
- TIME_PER_HOUR: Hour which the passenger trip is based on, in intervals from 0 to 23 hours
- PT_TYPE: Type of public transport, i.e. bus
- ORIGIN_PT_CODE: Origin bus stop ID
- DESTINATION_PT_CODE: Destination bus stop ID
- TOTAL_TRIPS: Number of trips We also note that values in ORIGIN_PT_CODE and DESTINATON_PT_CODE are in numeric data type. These should be in factor data type for further processing and georeferencing.
as.factor() can be used to convert the variables ORIGIN_PT_CODE and DESTINATON_PT_CODE from numeric to categorical data type. We use glimpse() again to check the results.
odbus$ORIGIN_PT_CODE <- as.factor(odbus$ORIGIN_PT_CODE)
odbus$DESTINATION_PT_CODE <- as.factor(odbus$DESTINATION_PT_CODE)
glimpse(odbus)Rows: 5,694,297
Columns: 7
$ YEAR_MONTH <chr> "2023-10", "2023-10", "2023-10", "2023-10", "2023-…
$ DAY_TYPE <chr> "WEEKENDS/HOLIDAY", "WEEKDAY", "WEEKENDS/HOLIDAY",…
$ TIME_PER_HOUR <dbl> 16, 16, 14, 14, 17, 17, 17, 7, 14, 14, 10, 20, 20,…
$ PT_TYPE <chr> "BUS", "BUS", "BUS", "BUS", "BUS", "BUS", "BUS", "…
$ ORIGIN_PT_CODE <fct> 04168, 04168, 80119, 80119, 44069, 20281, 20281, 1…
$ DESTINATION_PT_CODE <fct> 10051, 10051, 90079, 90079, 17229, 20141, 20141, 1…
$ TOTAL_TRIPS <dbl> 3, 5, 3, 5, 4, 1, 24, 2, 1, 7, 3, 2, 5, 1, 1, 1, 1…Note that both of them are in factor data type now.
In our study, we would like to analyse the 1 of the peak hour periods identified. We will be analysing the Weekday Morning peak periods thereafter. Therefore, we can employ a combination of the following functions to obtain the relevant data:
Summary of the functions used as follow:
filter(): Retains rows that satisfies our condition (i.e. Weekday Morning peak period)select()of dplyr package: Retains the desired variables for further analysis.group_by()andsummarise(): Aggregates the total trips at each combination of origin bus stop, destination bus stop, and peak period.
Let’s check the output using the glimpse() function of dplyr.
3.2 Geospatial Data
For the purpose of this exercise, three geospatial data will be used. They are:
- MPSZ-2019: This data provides the sub-zone boundary of URA Master Plan 2019, it helps us define the geographical boundary of Singapore.
- BusStop: This data provides the location of bus stop as at Jul 2023.
- Analytical hexagon: Hexagonal grids of 375m (this distance is the perpendicular distance between the centre of the hexagon and its edges) to represent the traffic analysis zone.
In this section, we import the shapefiles into RStudio using st_read() function of sf package. st_transform() function of sf package is used to transform the projection to coordinate reference system (CRS) 3414, which is the EPSG code for the SVY21 projection used in Singapore.
Reading layer `MPSZ-2019' from data source
`C:\kytjy\ISSS624\Take-Home_Ex\Take-Home_Ex2\data\geospatial'
using driver `ESRI Shapefile'
Simple feature collection with 332 features and 6 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 103.6057 ymin: 1.158699 xmax: 104.0885 ymax: 1.470775
Geodetic CRS: WGS 84In the code chunk below, tm_shape() of tmap package is used to define the input data (i.e mpsz) and tm_polygons() is used to draw the planning subzone polygons.
Reading layer `BusStop' from data source
`C:\kytjy\ISSS624\Take-Home_Ex\Take-Home_Ex2\data\geospatial'
using driver `ESRI Shapefile'
Simple feature collection with 5161 features and 3 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 3970.122 ymin: 26482.1 xmax: 48284.56 ymax: 52983.82
Projected CRS: SVY21Busstop represents sf point objects for 5161 bus stop in Singapore.
To visualise the points of the bus stops, we can use tm_shape() of tmap package with each bus stop point displayed as dots. tmap_mode allows us to view static maps with plot and interactive maps with view.
Show the code
Before proceeding, let’s check if there are any duplicated bus stops in the dataset.
bs_dupes <- busstop %>%
group_by(BUS_STOP_N) %>%
filter(n() > 1) %>%
ungroup() %>%
arrange(BUS_STOP_N)
knitr::kable(bs_dupes)| BUS_STOP_N | BUS_ROOF_N | LOC_DESC | geometry |
|---|---|---|---|
| 11009 | B04 | Ghim Moh Ter | POINT (23101.34 32594.17) |
| 11009 | B04-TMNL | GHIM MOH TER | POINT (23100.58 32604.36) |
| 22501 | B02 | Blk 662A | POINT (13489.09 35536.4) |
| 22501 | B02 | BLK 662A | POINT (13488.02 35537.88) |
| 43709 | B06 | BLK 644 | POINT (18963.42 36762.8) |
| 43709 | B06 | BLK 644 | POINT (18952.02 36751.83) |
| 47201 | UNK | NA | POINT (22616.75 47793.68) |
| 47201 | NIL | W’LANDS NTH STN | POINT (22632.92 47934) |
| 51071 | B21 | MACRITCHIE RESERVOIR | POINT (28311.27 36036.92) |
| 51071 | B21 | MACRITCHIE RESERVOIR | POINT (28282.54 36033.93) |
| 52059 | B03 | OPP BLK 65 | POINT (30770.3 34460.06) |
| 52059 | B09 | BLK 219 | POINT (30565.45 36133.15) |
| 53041 | B05 | Upp Thomson Road | POINT (28105.8 37246.76) |
| 53041 | B07 | Upp Thomson Road | POINT (27956.34 37379.29) |
| 58031 | UNK | OPP CANBERRA DR | POINT (27089.69 47570.9) |
| 58031 | UNK | OPP CANBERRA DR | POINT (27111.07 47517.77) |
| 62251 | B03 | Bef Blk 471B | POINT (35500.54 39943.41) |
| 62251 | B03 | BEF BLK 471B | POINT (35500.36 39943.34) |
| 67421 | B01 | CHENG LIM STN EXIT B | POINT (34548.54 42052.15) |
| 67421 | NIL | CHENG LIM STN EXIT B | POINT (34741.77 42004.21) |
| 68091 | B01 | AFT BAKER ST | POINT (32164.11 42695.98) |
| 68091 | B08 | AFT BAKER ST | POINT (32038.84 43298.68) |
| 68099 | B02 | BEF BAKER ST | POINT (32154.9 42742.82) |
| 68099 | B07 | BEF BAKER ST | POINT (32004.05 43320.34) |
| 77329 | B01 | BEF PASIR RIS ST 53 | POINT (40765.35 39452.18) |
| 77329 | B03 | Pasir Ris Central | POINT (40728.15 39438.15) |
| 82221 | B01 | BLK 3A | POINT (35323.6 33257.05) |
| 82221 | B01 | Blk 3A | POINT (35308.74 33335.17) |
| 96319 | NA | Yusen Logistics | POINT (42187.23 34995.78) |
| 96319 | NIL | YUSEN LOGISTICS | POINT (42187.23 34995.78) |
| 97079 | B14 | OPP ST. JOHN’S CRES | POINT (44144.57 38980.25) |
| 97079 | B14 | OPP ST. JOHN’S CRES | POINT (44055.75 38908.5) |
The results displayed 16 pairs of duplicated BUS_STOP_N, with each pair showing a different geometry point for the same bus stop number. This could potentially suggest that these are temporary bus stops. In that case, it would be prudent to retain only one of them, as conventionally, only one bus stop is used at a time.
Notice that the number of bus stops has dropped from 5161 to 5145.
Note from the choropleth map that there are 5 bus stops located outside Singapore, they are bus stops 46239, 46609, 47701, 46211, and 46219. The code chunk below uses filter() to exclude the 5 bus stops outside Singapore.
Notice that the number of bus stops has dropped from 5145 to 5140.
A hexagonal grid is used to represent the traffic analysis zones, which helps to model travel demand through capturing the spatial aspects of trip origins and destinations.
Step 1: Create Hexagonal Grids
We first create a hexagonal grid layer of 375m (refers to the perpendicular distance between the centre of the hexagon and its edges) with st_make_grid, st_sf to convert the grid into an sf object with the codes below, and row_number() to assign an ID to each hexagon.
st_make_grid function is used to create a grid over a spatial object. It takes 4 arguments, they are:
x: sf object; the input spatial data
cellsize: for hexagonal cells the distance between opposite edges in the unit of the crs the spatial data is using. In this case, we take cellsize to be 375m * 2 = 750m
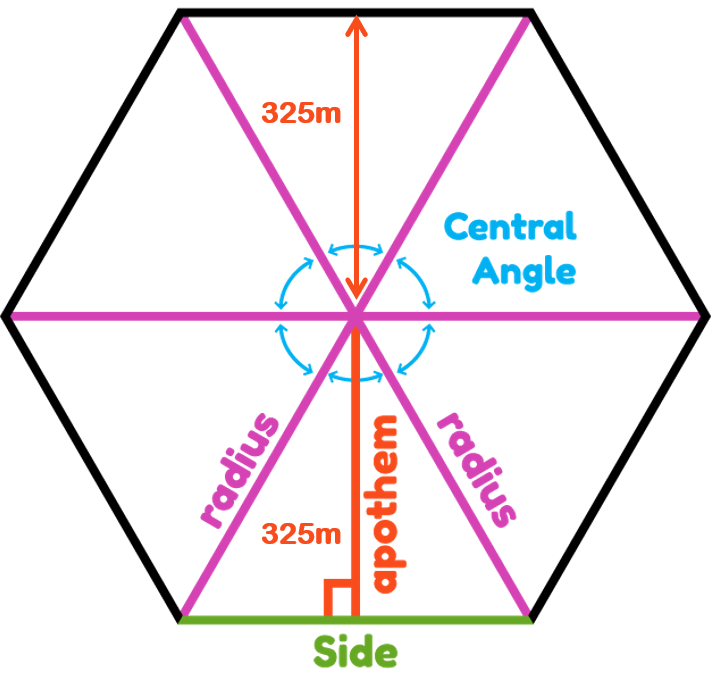
- what: character; one of:
"polygons","corners", or"centers" - square: indicates whether you are a square grid (TRUE) or hexagon grid (FALSE)
Step 2: Remove grids with no bus stops
We count the number of bus stops in each grid and retain only the grids with bus stops using the code chunks below.
st_intersects is used to identify the bus stops falling inside each hexagon, while lengths returns the number of bus stops inside each hexagon.
Notice that 831 hexagons have been created.
Step 3: Check & Visualise
Note that there are 5140 bus stops, which tallies to the 5140 from the Busstop shape file after deducting for the 5 bus stops outside Singapore boundary and the 16 duplicates, suggesting that the hexagons have managed to capture all expected bus stops.
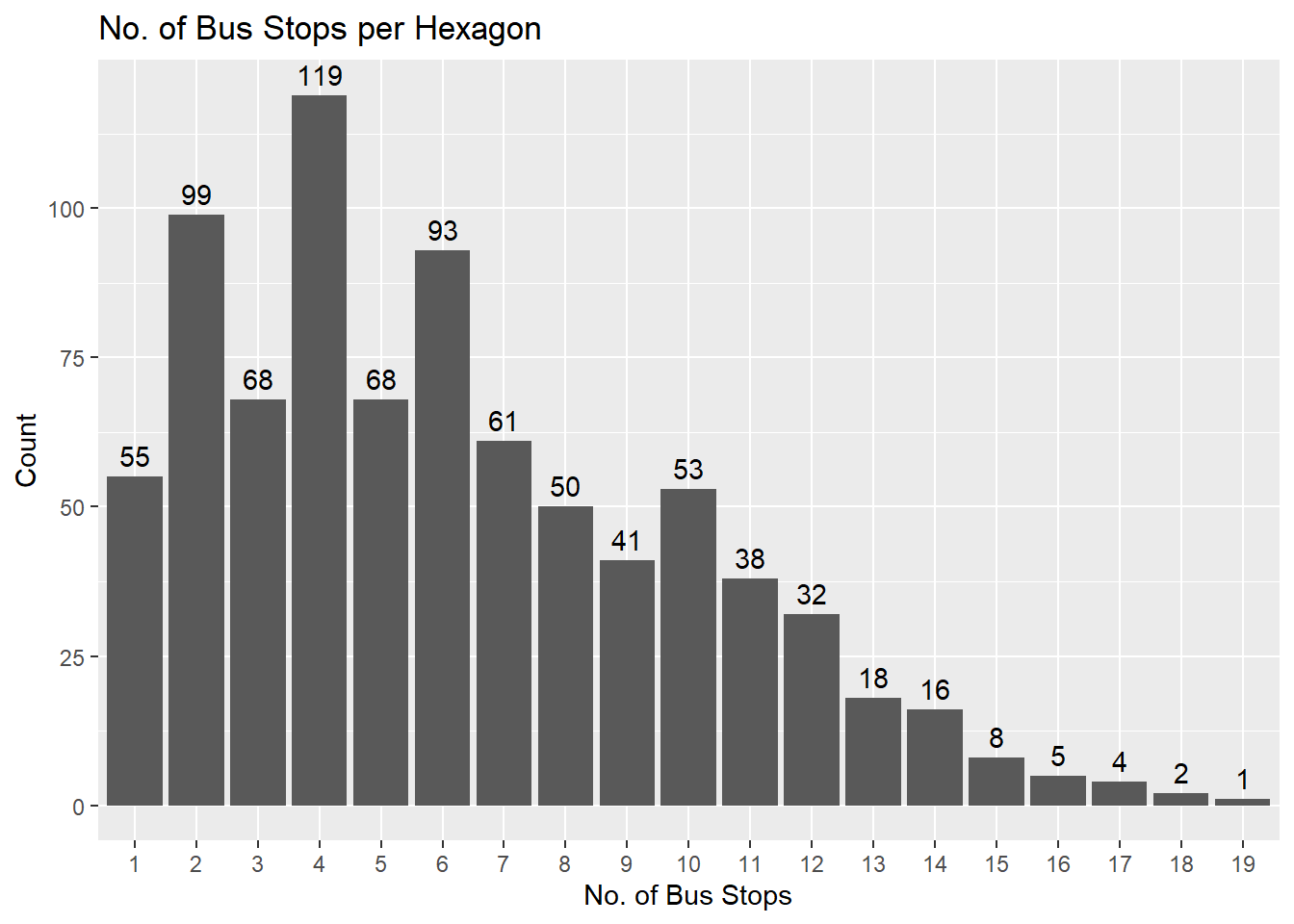
In the bar chart below, it is evident that the distribution of bus stops per hexagon is right-skewed. While one hexagon contains as many as 19 bus stops, the majority have fewer than 10 bus stops.
Show the code
Lastly, using tm_shape from tmap package, we can quickly visualise the results of the hexagon grids we have created.
Show the code

3.3 Geospatial Data Wrangling
3.3.1 Combining Busstop and Hexagons
Code chunk below populates the grid ID (i.e. grid_id) of area_hexagon_grid sf data frame into busstop sf data frame using the following functions:
st_intersection()is used to perform point and polygon overly and the output will be in point sf object.select()of dplyr package is then use to retain preferred variables from the data frames.st_stop_geometry()removes the geometry data to manipulate it like a regular dataframe usingtidyranddplyrfunctions
Before we proceed, let’s perform a duplicates check on bs_wgrids.
# A tibble: 0 × 4
# ℹ 4 variables: BUS_STOP_N <chr>, BUS_ROOF_N <chr>, LOC_DESC <chr>,
# grid_id <int>Results showed that there are no duplicated records.
3.3.2 Populate Passenger Volume data with Grid IDs
Next, we are going to append the Grid IDs based on origin bus stops from bs_wgrids data frame onto WDMpeak data frame. But before that, ensure that BUS_STOP_N of bs_wgrids is also in factor data type.
Next, we will update od_data data frame with the Grid IDs of destination bus stops.
od_data <- left_join(od_data , bs_wgrids,
by = c("DESTIN_BS" = "BUS_STOP_N")) %>%
rename(DESTIN_GRID = grid_id,
DESTIN_DESC = LOC_DESC)
glimpse(od_data)Rows: 242,208
Columns: 9
Groups: ORIGIN_BS [5,029]
$ ORIGIN_BS <fct> 01012, 01012, 01012, 01012, 01012, 01012, 01012, 01012, 0…
$ DESTIN_BS <fct> 01112, 01113, 01121, 01211, 01311, 07371, 60011, 60021, 6…
$ TRIPS <dbl> 290, 118, 77, 118, 165, 14, 30, 16, 35, 26, 2, 8, 1, 2, 2…
$ BUS_ROOF_N.x <chr> "B03", "B03", "B03", "B03", "B03", "B03", "B03", "B03", "…
$ ORIGIN_DESC <chr> "HOTEL GRAND PACIFIC", "HOTEL GRAND PACIFIC", "HOTEL GRAN…
$ ORIGIN_GRID <int> 1334, 1334, 1334, 1334, 1334, 1334, 1334, 1334, 1334, 133…
$ BUS_ROOF_N.y <chr> "B07", "B09", "B11", "B13", "B01", "B01", "B01", "B03", "…
$ DESTIN_DESC <chr> "OPP BUGIS STN EXIT C", "BUGIS STN EXIT B", "STAMFORD PR …
$ DESTIN_GRID <int> 1354, 1354, 1392, 1392, 1411, 1411, 1393, 1431, 1450, 143…The code chunk below allows us to check for duplicates to prevent double counting. The results indicate that there are no duplicates found.
# A tibble: 0 × 9
# ℹ 9 variables: ORIGIN_BS <fct>, DESTIN_BS <fct>, TRIPS <dbl>,
# BUS_ROOF_N.x <chr>, ORIGIN_DESC <chr>, ORIGIN_GRID <int>,
# BUS_ROOF_N.y <chr>, DESTIN_DESC <chr>, DESTIN_GRID <int>Next, the code chunk below removes rows with missing data using drop_na() and aggregates the total passenger trips at each origin-destination grid level with group_by() and summarise(). ORIGIN_nBS and DESTIN_nBS counts the number of bus stops, while ORIGIN_DESC and DESTIN_DESC provides the descriptions of each of the bus stops at origin and destination grids respectively.
od_data <- od_data %>%
drop_na() %>%
group_by(ORIGIN_GRID, DESTIN_GRID) %>%
summarise(MORNING_PEAK = sum(TRIPS),
ORIGIN_nBS = n_distinct(ORIGIN_BS),
ORIGIN_DESC = str_c(unique(ORIGIN_DESC), collapse = ", "),
DESTIN_nBS = n_distinct(DESTIN_BS),
DESTIN_DESC = str_c(unique(DESTIN_DESC), collapse = ", ")) %>%
ungroup()Our resulting OD Matrix organises the commuter flows for weekday morning peak period in a column-wise format, with origin_grid representing the from and destin_grid representing the to. There are a total of 65,559 unique origin grid to destination grid combinations.
4 Visualising Spatial Interaction
Origin-destination flow maps are a popular option to visualise connections between different spatial locations. It reflects the relationships/flows between locations and are created by monitoring movements. In our analysis, we can use OD flows to identify the patterns of bus ridership during weekday mornings.
4.1 Identifying Inter- & Intra-Zonal Flows
Intrazonal travels are considered localised and short duration trips within a transportation analysis zone (i.e. within a hexagon). For our analysis, we will be separating them.
To do that, we create a new column in the od_data dataframe called Zone_Type using mutate() that labels each row as either “Intrazone” or “Interzone” based on whether the ORIGIN_GRID and DESTIN_GRID are the same or different.
There are 623 combinations of intra-zonal travels and 64,936 combinations of inter-zonal travels during the weekday morning peak period based on our dataset.
4.2 Interzonal OD Flow Distribution
In the code chunk below, we use filter() to identify the inter-data before using summary() to evaulate the distribution of data.
Show the code
0% 5% 10% 15% 20% 25% 30% 35% 40% 45% 50% 55% 60%
1 1 2 3 5 7 11 15 21 28 37 50 67
65% 70% 75% 80% 85% 90% 95% 100%
90 124 174 252 388 658 1399 77433 From the summary statistics provided above, we observe that the minimum number of passenger trips for each interzonal combination of origin and destination bus stop is 1. The maximum number of trips recorded is 77,433 passengers, noted during the weekday morning peak period. Additionally, the 90th percentile for passenger trips stands at 174, indicating a highly right-skewed distribution.
4.2 Creating Interzonal Flow Lines
Desire lines visually represent the connections between originating and destination hexagons using straight lines. The od2line() function of stplanr package is utilized to create these lines. The width of each desire line is proportional to number of passenger trips, i.e. thicker lines would represent higher ridership.
Since there are 65,559 different flow lines resulting from combinations of origin to destination hexagons, an excess of intersecting lines can cause visual clutter and obscure analysis. Considering that the 90th percentile is 658, we will focus on inter-zonal flows with the top 10% of ridership.
Show the code
tmap_mode("view")
tmap_options(check.and.fix = TRUE)
#tm_basemap("OneMapSG.Grey") +
tm_basemap("OpenStreetMap") +
tm_shape(mpsz) +
tm_polygons(col='#C2D3CC', border.alpha = 0.1, alpha = 0.3) +
tm_shape(area_hexagon_grid) +
tm_fill(alpha=0.7,
palette="RdBu") +
tm_borders(alpha = 0.5)+
flowLine %>%
filter(MORNING_PEAK >= 659) %>%
tm_shape() +
tm_lines(lwd = "MORNING_PEAK",
style = "quantile",
scale = c(0.1, 1, 3, 5, 7, 10),
n = 6,
alpha = 0.3,
lines.lwd = "all",
popup.vars = c("No. of Bus Stops at Origin: " = "ORIGIN_nBS",
"Descriptions of Bus Stops at Origin: " = "ORIGIN_DESC",
"No. of Bus Stops at Destination: " = "DESTIN_nBS",
"Descriptions of Bus Stops at Destination: " = "DESTIN_DESC",
"No. of Passenger Trips :" = "MORNING_PEAK"))